Not quite an award: we were shortlisted in the ‘Technological Innovation’ category for our Orange Film Pulse project. We were in pretty auspicious company, so just getting on the shortlist made us happy.
Smesh Blog
Revolution award
Hot on the heals of its Data Strategy Award, the Orange Flickometer has won a prestigious Revolution Award for best use of data visualisation. The revolution awards celebrate innovation in digital marketing, which is exactly what the Flickometer project represents.
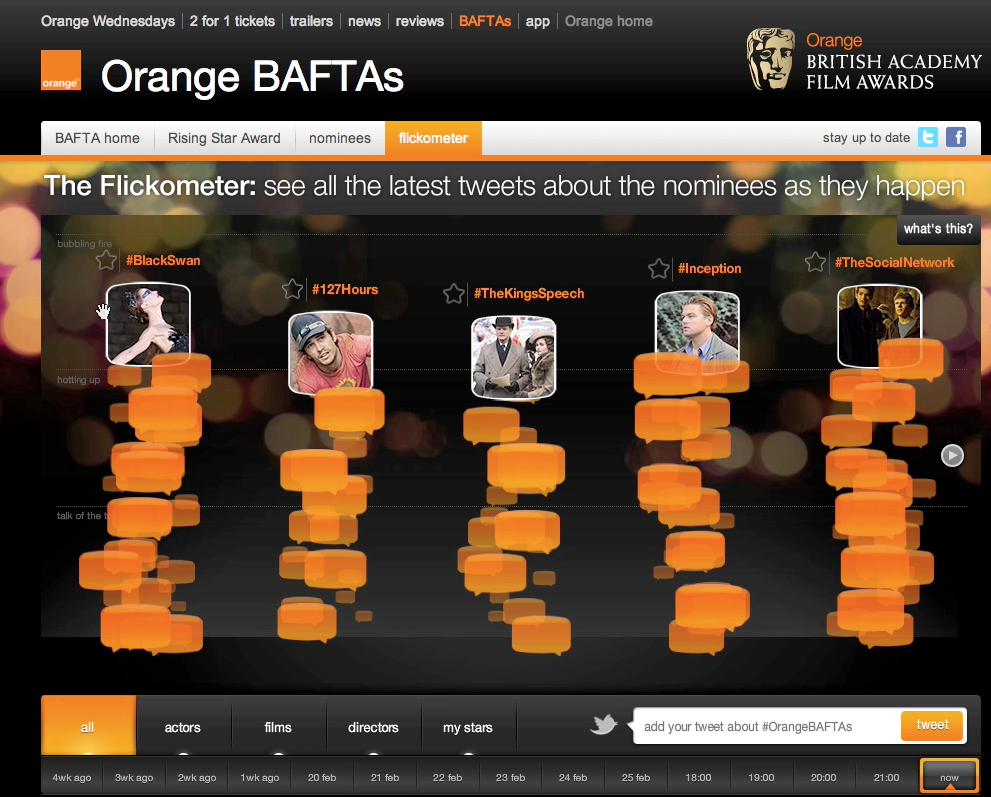
Produced for the 2011 BAFTA film campaign, the Flickometer measured the online buzz around BAFTA nominated films, actors and directors and presented the data in a fun and interactive way. The tool also allowed users to compare the change in buzz over several weeks leading up to the BAFTA event and to get involved themselves by tweeting from the site.
Smesh provided the social data backend for the project, and we share our congratulations with creative and build partners Poke and Sennep.
Data Strategy Award
Smesh was thrilled to bits to win a Marketing Week Data Strategy Award for the Flickometer, which we developed for Orange’s 2011 BAFTA campaign, supported by production and design work from Poke and Flash build by Sennep.

- L-R: Generous sponsor man, Liza from Orange, Tom from Smesh, Ruby Wax. “Gottle a geer,” says Ruby.
It is a universally acknowledged fact that nothing says ‘glamour’ like Data Strategy; something that Ruby remarked upon in various creative ways throughout the evening. Ruby looked a bit troubled when Liza from Orange, actually looking glamorous, turned up with Tom to collect the award. “Are you with him??,” asked a disbelieving Ruby.
Tom’s sense of outrage was soothed when the otherwise generously-proportioned Ruby had to stand on a plastic crate for the photo above.

- Pre-award dinner and pensive anticipation. L-R Liza from Orange, Brad from Poke, Stuart from Sennep.

Smesh looks forward to doing more interesting work with creative partners for forward-thinking clients; awards always a nice bonus.
Why buzz monitoring tools have different results
When people use tools for monitoring social media content, such as Brandwatch, Radian6 or our own Smesh technology, they expect that the different tools should all produce very similar or identical results for any given term being monitored and are a bit surprised when they don’t. They’re all looking at the same content, aren’t they? The stuff that’s out there on the web?
Perhaps surprisingly, though hopefully less surprising once you’ve read this, the answer is ‘no': they’re not all looking at the same content and will frequently produce differing results.
There are many different aspects of how tools work that can lead to big differences in results. This posting tries to explain a few of the major ones in layman’s terms. Perhaps a web-obsessed layman, rather than your regular kind.
A bit of understanding about what goes on under the hood of monitoring tools will also help you to ask wholesomely difficult questions next time someone tries to sell you social media monitoring services.
Very broadly, two key factors, which we’ll look at in a bit more detail shortly are:
- what data gets fed into the system in the first place?
- how do searches get run against the data in the system?
What data gets fed into the system in the first place?
Big search engines like Google, Yahoo and Bing devote, to adopt non industry-standard terminology, honking great dollops of infrastructure to finding (‘crawling’) and storing for search (‘indexing’) all of the publicly visible pages on the web, along with RSS feeds and some other types of data. These are ‘full web indexes’.
Most social media companies simply don’t have the large scale infrastructure needed to run their own full web indexes, so they use other techniques instead — which has a huge impact in terms of what data is available in their tools in the first place. A typical social media monitoring solution will have its own small-scale index (typically millions as opposed to billions of items), and try to ensure that this contains as much relevant data for users as possible.
Here are some of the common approaches to getting hold of relevant web data to put into a small-scale index without having to be Google- or Yahoo-sized. This variation in the sourcing of data contributes massively to variation in the search results that end users of social media monitoring tools see, because these different techniques provide varying data.
Use someone else’s full web index
Yahoo has a full web index going back years that you can run queries against on a commercial basis; there aren’t many competitor services; it’s also not clear exactly where the future of this specific service lies now that Yahoo are passing responsibility for search results to Microsoft. Note that Google generally doesn’t let commercial service providers use their index; mostly they just want individual humans who they can serve ads to looking at their results.
Using someone else’s index, you’re stuck with their techniques for deciding just how relevant given pieces of content are; if their results suck, yours probably will too. You can get round this to some extent by first slurping results into your own small-scale search system; but still, if the incoming data is bad, you’ll struggle to provide quality data going out.
Piggyback on someone else’s search results
A variant of the above, a bit like meta-search from days of yore. See what results other search engines supply and either use these as ‘your’ results (legally dubious), or less dubiously, use the results as an indicator of web sites to grab content from yourself, without having to crawl the whole web.
Buy a 3rd party data feed
Various providers (e.g. Moreover, Spinn3r) offer data feeds that tool vendors can consume some or all of, containing data from a wide range of sources and often with additional layers of data (data about the data, called ‘meta-data’) added, such as categorisation information for sites. Of course, a ‘wide range of sources’ as provided by such tools isn’t ‘the entire web’ so risks missing relevant content, and the various services typically have their own strengths and weaknesses when it comes to things like filtering out spam and adding or discovering new sources.
Constrained crawling
Find (‘crawl’) and index everything for yourself, but heavily constrain this process so that you don’t fall down the rabbit hole of trying to crawl the entire web. This approach can be used effectively in tandem with ‘piggybacking’ (above) — you might sneak a peek at search engine results for a query, then grab data from the web pages that are mentioned, plus all of the pages that those pages have links to, but no more than that.
Managed crawling services
There are some new services (e.g. 80legs) that offer hosted crawling — instead of trying to manage your own servers for crawling and indexing, you pay someone else to do it for you. You just define what sources you want to look at, and then get results back. This still involves constraining what sources you’re looking at though, unless a) you have a very large budget and b) the provider can actually offer full web indexing.
It’s not hard to see how if different tools use very different approaches to getting hold of data, then they’re not going to be looking at the same content, and won’t be able to show the same results to their users, even for identical queries.
How do searches get run against the data in the system?
All of the above epic nerdery gets your social media monitoring system a pile of data that you can search, analyse and generally rummage around in to find information to show to your users.
Variations in how different tools set about this rummaging around is another major source of variation in their results. Even if all tools used exactly the same approach to get hold of content in the first place (the processes described above), they’d still end up showing different results through using different technologies and techniques for deciding what items to subsequently show to users for their queries.
Typically, any given monitoring tool will be using some kind of search index, which is a special kind of database for handling search-engine style queries. Differences between the various indexing tools used produces differences in results. Even if all of the tool vendors used the same method for getting hold of data and exactly the same indexing technology, you’d *still* see a lot of variation in results, because there are loads of ways you can ‘tweak’ the results you get out of search index.
For example, one vendor might attach more significance to how recent query results are; another might decide that the search term appearing in a web page’s title is massively significant where the first decides it is less so. Although these variations sound small, they can have a big impact on the quality of results presented back to users; there is lots of scope for variation even within a single search technology.
In fact, different vendors probably use different indexing systems, have different approaches to filtering out spam, keep data for varying periods of time, and so on.
To return to our original question, different tools can be given the same query, but despite the world’s wider Web being largely the same for each, the content that they’re actually using to find results for you and the tools and techniques that they’re using to do differ wildly.
To resort to a terribly contrived analogy, imagine sitting two different artists down in front of the same sunflower and asking them the paint a picture of it — despite both being given the same instructions and being faced with the same object, the end results are likely to be wildly different (especially if one of them is a depressive genius prone to hacking off parts of his own body). You might object that something like social media buzz monitoring must surely be scientific. However, the mere involvement of computers doesn’t make something scientific, and there is so much leeway for variation and creativity in how such systems are actually built that there is actually a large degree of artistry involved.
Difficult questions
As for those ‘wholesomely difficult questions’ to ask next time someone tries to sell you social media monitoring services, draw on the above and see if you can get a detailed account of their data:
- Where exactly does their data come from?
- How often does it get updated?
- Do they include Twitter and Facebook? If so, how much of them?
- When you add a query, how do they decide what results to show you? Do you have any control over this?
If you’re told that they index the entire internet in real-time (which at time of writing even the mighty Google don’t do), then you can probably draw your own conclusions about their sales practices. Similarly if they haven’t a clue how to answer.
Social network futures: information wants to roam free
The Internet tends towards open standards where its infrastructure is concerned, not least because there are so many different interest groups operating on the net who stand to benefit (though of course there are massive tussles over lower-level technology that place restrictions on usage, such as DRM on video, music and games). There follows some musing on what is happening in this regard in the space of social media and where such activities are leading.
Background: niches and walls
[Personal anecdotal content; may not be quite correct] Back in the 1990s, if you were an AOL user, you could only access your email using proprietary AOL tools and were encouraged to browse sites that existed within a walled-garden of AOL-approved content. This worked fine for AOL, as it gave them a lot of control over users, and they could ensure that these users saw AOL’s choice of ads while they were doing things within the online space that AOL defined.
This didn’t last for very long. People wanted to be able to access their AOL email using rapidly improving 3rd party email clients (a ‘client’ typically being a piece of software used to access an online service), such as Netscape mail and Microsoft’s then popular Outlook and Outlook Express. AOL ended up adopting email standards such as POP3 to enable this to happen, otherwise users would have migrated to other, more open email service providers, which many did anyway in the time it took for these changes to happen. Similarly with AOL’s walled garden of sites. Users wanted to be able to browse the web freely, and lots of sites out there wanted to attract users to then make money, either by selling them stuff or showing them ads. People just used their own browsers via their AOL internet connection instead of using the official AOL browser app.
Having limited, controlled, walled content seemed fairly reasonable at the beginning, when email was a niche, specialised service alongside Bulletin Board Systems (BBS), Internet Relay Chat (IRC) and Usenet groups; similarly there weren’t that many Web sites out there.
Knocking down walls for fun and profit
As email and web browsing became well-defined things that everyone wanted to do lots of the time, having walls became problematic and the barriers were pushed down.
Even when a technical protocol for doing something isn’t opened up, people invent technologies to bridge closed things to open things. For example, Instant Messaging has standardised around XMPP. Where some IM networks haven’t embraced this open standard, there are technologies now built into the open standard so that these proprietary IM networks can be accessed via XMPP.
Pressure to be open
Very generally, there’s a process as follows that happens, again and again:
1. Some specific app, whose ultimate popularity is unknown, gets built using existing tools, but isn’t particularly ‘open’ — this happened with HTML and IM for example.
2. If the app is massively adopted, it becomes a ‘thing’ in its own right (perhaps just an accepted way of doing some kind of stuff), with pressure for it to be defined by a set of standards that users and tech providers across the ‘net can tap into.
3. If the creator of the initial ‘thing’ doesn’t keep up, it gets sidelined as the benefits associated with participating in the open form of whatever-it-is increases and open alternatives build up market share.
Facebook’s high walls
Something similar is happening right now with social networks.
Currently, Facebook (FB) is the ultimate social network walled garden; an entire ecosystem in its own right. FB wants to keep all of the substantial revenues associated with having a vast and highly engaged user base, so it has built the walls very high.
Twitter is similar, though the walls are built very low indeed, with stiles placed at strategic intervals to help content move freely across it. Twitter has very accommodating APIs to help 3rd party developers tap into its functionality; this is a common commercial approach to reducing the motivation to build open versions of things; Google use this technique a lot too.
The problem for FB especially (with its very high walls), is that social networking has moved from being a quirky niche application that a few websites provide, to being a fairly well-defined ‘thing in its own right’, understood by a large portion of web users.
Broadly, the social network ‘thing’ goes like this. There are a bunch of people with connections between them of various types. This is the ‘social graph’, based on friendship, family membership, business connections and so on. Individuals create content: they write status messages, add calendar entries, mark sites as favourites. This spreads out to some number of their contacts based on the creator’s preference and privacy settings, and then their connected contacts’ settings.
Open standards for social networks
There is now a lot of momentum behind the scenes attempting to define open standards for these entities: people, connections, events / activities, and so on.
One of the leading contenders is ActivityStreams
(http://activitystrea.ms/), which Google has a hand in. Google generally benefits more from the flow of information — to which advertising can be attached — than from specific applications, so they tend to embrace open standards. Once information is publicly accessible, Google can index it and so provide search results for that data, with revenue-generating ads alongside. Plus they’re pretty good at building browser-based versions of apps (e.g. gmail for email), which they can serve another layer of revenue-generating ads into, on top of what they do with search results.
There is likely to be rapid adoption of open standards in this area, as pretty much everyone bar FB stands to benefit from it. Users will have more control over and ownership of their information, and commercial outfits will be able to make money from a range of value-added (or just ad-added) services without having to digest arcane and restrictive Terms of Service and deal with ever shifting and breaking APIs.
Right now we mostly have ‘pretend’ integration between different social networks. Apps like TweetDeck pull ‘your’ content from different sources into a single UI, but have use completely different APIs and techniques behind the scenes to do so; users have to set up Twitter to repost Tweets to FB; and so on. These are resource-intensive work-arounds for the lack of common standards.
Impending changes
This shifting landscape will bring an interesting challenge to FB. As other existing and new networks open up, with the weight of the likes of Google behind them, and compelling apps are built that tap into these networks, FB as a destination will start to feel isolated and stagnent if it doesn’t open up too. If they do open up their content, then they won’t be able to monopolise it in the way they do at present.
As incentives for open social networking standards increase, we’re likely to see:
- Proliferation of 3rd party apps (both desktop and online) for managing and mashing up data across networks
- More consistent APIs available on existing social networks (as OpenSocial seeks to do)
- Increasingly defensive Terms of Service from big networks like FB, attempting to guard the commercial value of data that they’re being compelled by the market to expose
- Ads networks and producers of ads will try harder to tap into social media
- New ad networks and formats will emerge that have been designed with social media engagement in mind
Longer term / smoking crack
Predicting the future around technology tends to be a waste of time, because technologies and social trends come along and engage with one another, having a transformative rather than linear or additive effect. But here goes.
From my experience at Poke, I see how digital campaigns increasingly involve a degree of integration with social networks. If you can create genuinely compelling and engaging content that plays to the strengths of social networks (sharing, competing, etc.), or is just novel and fun, then you get a lot of return for your investment compared to the cost/benefit of building a standalone microsite and paying for a load of banner ads. People are their own distribution network (peer to peer, pretty much literally), but have to have a motive for distributing things.
If you combine a trend towards more decentralised, open and peer-based content with the rise of mobile computing (from high-end handsets to new devices like the iPad), you end up with a world that looks a lot like original visions for RSS and the semantic web that didn’t or haven’t yet come to be. Content flows to the user from a broad range of sources (friends, news outlets, brands, etc.), can be fairly ‘rich’ thanks to increasing HTML5 support (video, apps that work offline) and back out again.
The deluge problem (too many emails, too many RSS feeds) is to some extent ameliorated by application of the social graph. For example, for many sources of information, I don’t even want to see what they’ve got to say unless someone I trust gives some item a thumbs-up. In contrast, my girlfriend’s merest expression of online whimsy needs to be readily available to me, lest I be deemed oblivious to her life while chatting to her after work.
Er, the end. Which of course it isn’t.